1. Configure API Keys
Evals use OpenAI, so you need to configure your OpenAI API key. If you wish to view the results on Athina Develop, and maintain a historical record of prompts and experiments you run during your development workflow, then you also need an Athina API Key.2. Load your dataset
Loading a dataset is quite straightforward - we support JSON and CSV formats.3. Run an eval on a dataset
Running evals on a batch of datapoints is the most effective way to rapidly iterate as you’re developing your model.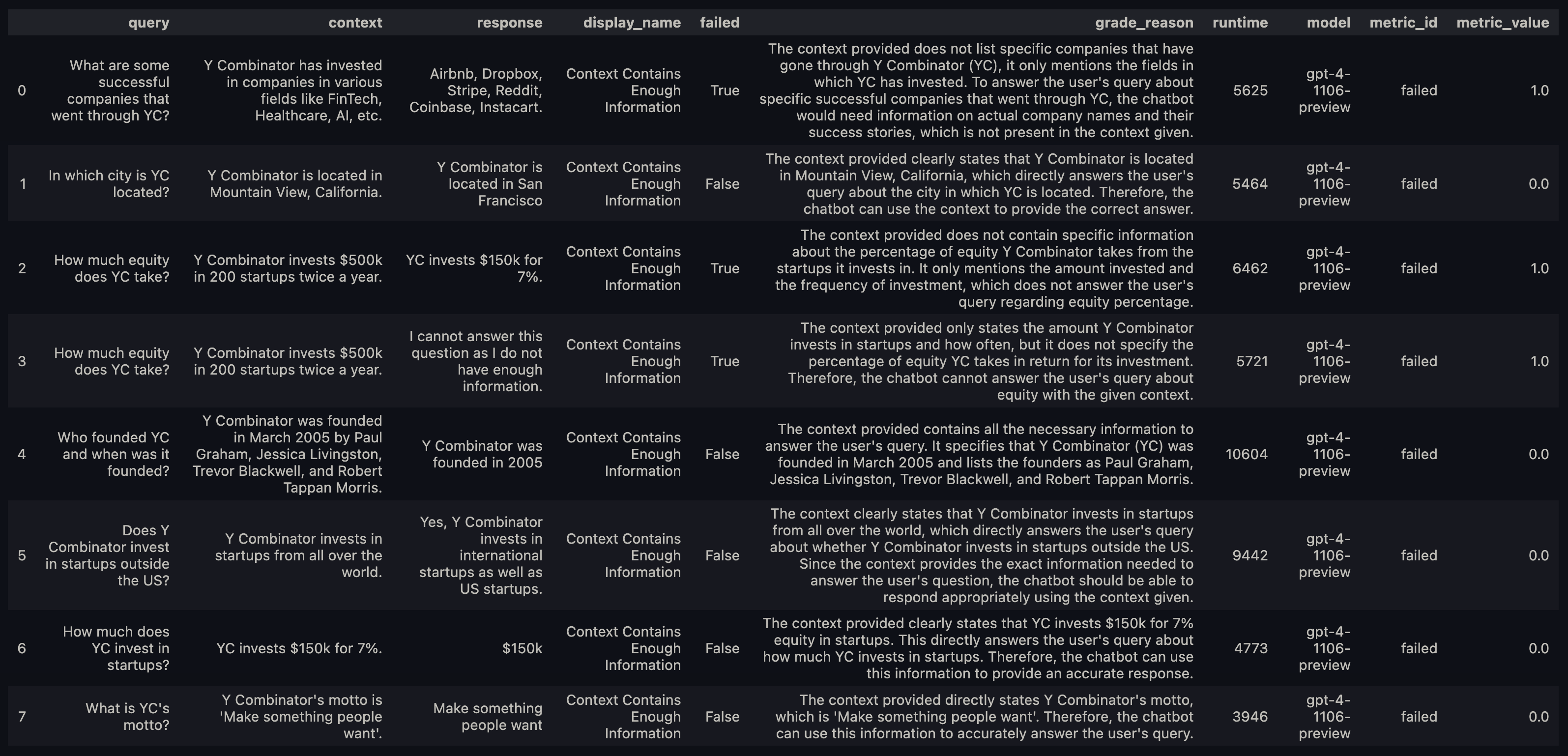
How do I know which fields I need in my dataset?
Every evaluator has a
REQUIRED_ARGS property that defines the parameters it expects.
If you pass the wrong parameters, the evaluator will raise a ValueError telling you what params you are missing.
For example:, the Faithfulness evaluator expects response and context fields.