❊ Info
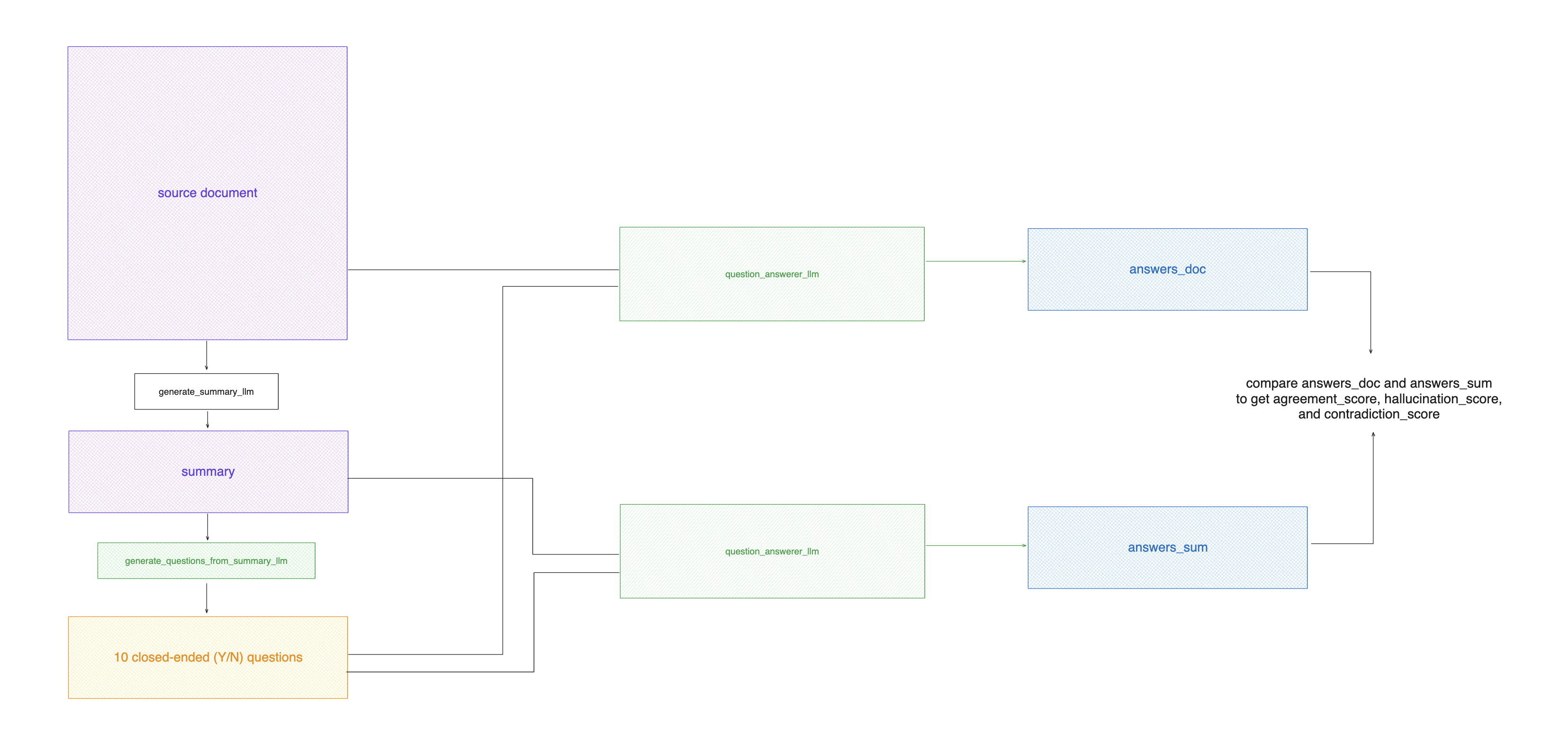
This evaluator checks for inaccuracies or hallucinated information in summaries. How does it work This evaluator compares the information between a sourcedocument and an LLM-generated summary.
- Generates N closed-ended (Y/N/Unknown) questions from the
summaryinformation. QuestionAnswererLLM is used to answer each question given ONLY thesummaryas context.QuestionAnswererLLM is used to answer each question given ONLY the sourcedocumentas context.- Compare the answers from the
summaryanddocumentfor each question to find contradictions.
 Required Args
Your dataset must contain these fields:
Required Args
Your dataset must contain these fields:
document: The source document that contains the information that should be summarized.response: The LLM generated summary of the source document.
gpt-3.5-turbo
Metrics
Agreement Score: The percentage of questions that had identical answers for both contexts.Hallucination Score: The percentage of questions where the summary answered A definitively (Y/N) but the source document answered “Unknown”.Contradiction Score: The percentage of questions where the summary answered A definitively (Y/N) but the source document answered definitively B (Y/N).
▷ Run the eval on a single datapoint
▷ Run the eval on a dataset
- Load your data with the
SummaryLoader
- Run the evaluator on your dataset
⚙︎ Configuration options
n_questions: int
Number of questions to generate.
More questions = more accurate, granular evaluations, but it will also mean higher evaluation time, and LLM inference cost.
questions: List[str]
If you would like to ask custom questions instead of generating the questions, you can provide a list of questions using the constructor argument questions.
question_answerer: QuestionAnswerer
You can also configure which LLM prompting technique to use for answering questions:
QuestionAnswererBulk(faster, cheaper, default): uses a single prompt to answer all the questions.QuestionAnswererChainOfThought(slower, uses more tokens, better reasoning): will prompt the LLM separately for each question, wrapped in a chain of thought prompt.QuestionAnswererWithRetrieval: (good for large documents) uses a simple similarity search to narrow-down context.
QuestionAnswererChainOfThought:
Example
Document: Meeting Transcript
Alice (Veterinarian): Hi Bob, I understand you’re looking to get a new dog. It’s great that you’re considering different breeds like Golden Retrievers, Labradors, and French Bulldogs. Let’s discuss what you’re looking for in a dog to help you make the best choice.
Bob: Thanks, Alice. I’m really looking for a breed that’s hypoallergenic and doesn’t shed much. Also, it’s important that the dog is friendly and non-aggressive towards other people.
Alice: Those are important considerations. Let’s start with Golden Retrievers and Labradors. Both are known for their friendly and outgoing nature, which means they generally get along well with people and other pets. However, they are not hypoallergenic and do tend to shed quite a bit.
Bob: I see, that’s a bit of a concern for me. What about French Bulldogs?
Alice: French Bulldogs are a bit different. They’re smaller and have a playful, affectionate personality. They tend to shed less than Golden Retrievers and Labradors, but they’re not entirely hypoallergenic either. One thing to note is that they can be quite stubborn, which requires consistent training.
Bob: That’s helpful to know. I really need a hypoallergenic breed due to allergies. Are there any breeds you would recommend that fit these criteria?
Alice: Absolutely, Bob. For hypoallergenic and low shedding breeds, you might want to consider Poodles, Bichon Frises, or Portuguese Water Dogs. These breeds are known for their friendly demeanor and are less likely to trigger allergies. They also require regular grooming to maintain their coat and minimize shedding.
Bob: That sounds more like what I’m looking for. I hadn’t thought about those breeds. I’ll definitely look into them. Thanks for your advice, Alice!
Alice: You’re welcome, Bob! Feel free to reach out if you have more questions or need help once you decide on a breed. It’s important to choose a dog that fits well with your lifestyle and needs.
Bob: Thanks, Alice. I’m really looking for a breed that’s hypoallergenic and doesn’t shed much. Also, it’s important that the dog is friendly and non-aggressive towards other people.
Alice: Those are important considerations. Let’s start with Golden Retrievers and Labradors. Both are known for their friendly and outgoing nature, which means they generally get along well with people and other pets. However, they are not hypoallergenic and do tend to shed quite a bit.
Bob: I see, that’s a bit of a concern for me. What about French Bulldogs?
Alice: French Bulldogs are a bit different. They’re smaller and have a playful, affectionate personality. They tend to shed less than Golden Retrievers and Labradors, but they’re not entirely hypoallergenic either. One thing to note is that they can be quite stubborn, which requires consistent training.
Bob: That’s helpful to know. I really need a hypoallergenic breed due to allergies. Are there any breeds you would recommend that fit these criteria?
Alice: Absolutely, Bob. For hypoallergenic and low shedding breeds, you might want to consider Poodles, Bichon Frises, or Portuguese Water Dogs. These breeds are known for their friendly demeanor and are less likely to trigger allergies. They also require regular grooming to maintain their coat and minimize shedding.
Bob: That sounds more like what I’m looking for. I hadn’t thought about those breeds. I’ll definitely look into them. Thanks for your advice, Alice!
Alice: You’re welcome, Bob! Feel free to reach out if you have more questions or need help once you decide on a breed. It’s important to choose a dog that fits well with your lifestyle and needs.
Response: LLM Generated Summary of Transcript
In this conversation, Alice, a veterinarian, and Bob discuss Bob’s desire to
get a new dog. Bob seeks a hypoallergenic breed that sheds minimally and is
friendly. Alice notes that Golden Retrievers and Labradors are friendly,
hypoallergenic and don’t shed a lot. French Bulldogs are less shedding but
also not completely hypoallergenic and can be stubborn. Alice then suggests
Poodles, Bichon Frises, or Portuguese Water Dogs as breeds fitting Bob’s
criteria: hypoallergenic, low shedding, and friendly. Bob appreciates the
advice and considers these options. Alice offers further assistance as needed.