Introduction
You can integrate Athina Tracing into your LLM applications with the Athina Python SDK using theobserve decorator.
Example
import os
import openai
from athina_logger.tracing.decorators import observe
from athina_logger.api_key import AthinaApiKey
AthinaApiKey.set_api_key(os.getenv("ATHINA_API_KEY"))
@observe.trace(name="main_process")
async def process_user_request(user_query: str):
processed_user_query = await preprocess(query=user_query)
chunked_user_query = await chunking(processed_user_query)
response = await generate_response(chunked_user_query)
return response
@observe.span(name="preprocess")
async def preprocess(query: str):
return query.strip().lower()
@observe.span(name="chunking")
async def chunking(query: str):
observe.update_current_span(
attributes={
"query_length": len(query),
}
)
return query[:35]
@observe.generation(name="generate_response")
async def generate_response(query: str):
model = "gpt-4o-mini"
messages = [
{"role": "system", "content": "You are a helpful assistant. Answer in a single sentence."},
{"role": "user", "content": query}
]
response = openai.chat.completions.create(
model=model,
max_tokens=100,
messages=messages,
)
observe.update_current_span(
attributes={
"user_query": query,
"prompt": messages,
"language_model_id": model,
"response": response.choices[0].message.content,
"prompt_tokens": response.usage.prompt_tokens,
"completion_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
}
)
return response.choices[0].message.content
async def main():
response = await process_user_request("What is the capital city of Sweden? Please")
print(response)
if __name__ == "__main__":
import asyncio
asyncio.run(main())
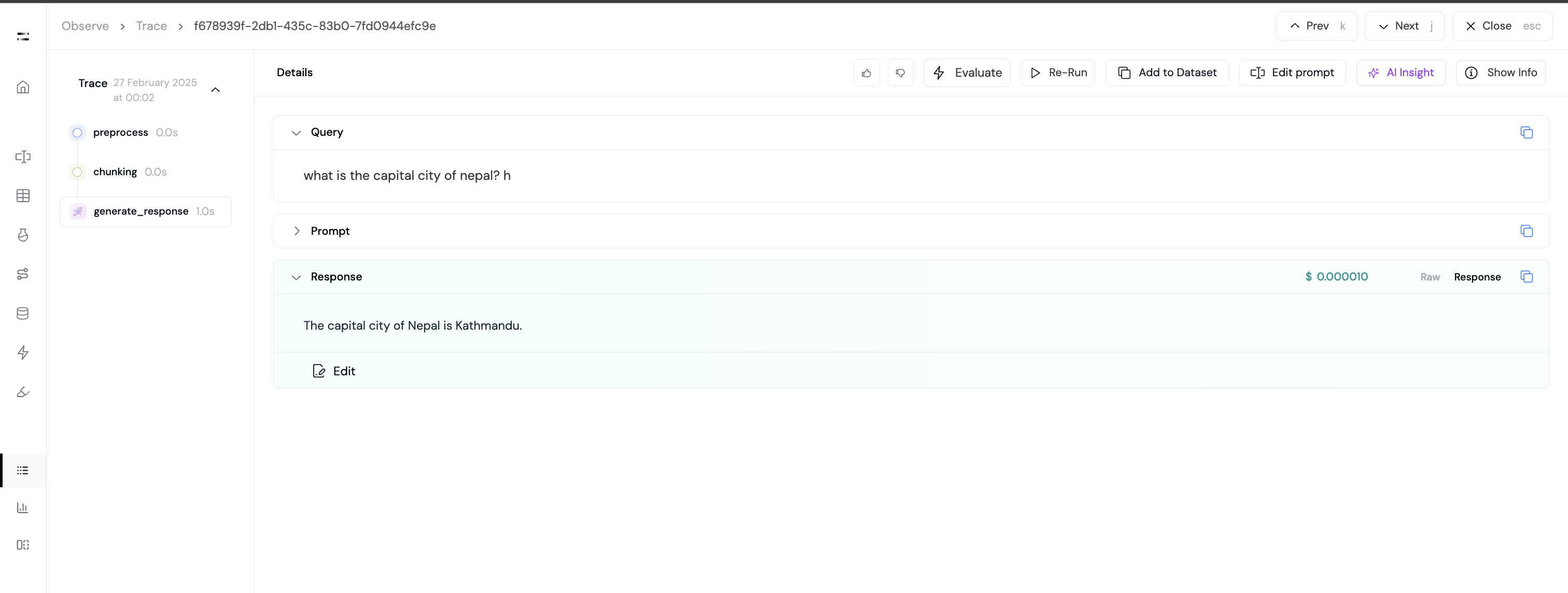
Trace in Athina UI
When logged to Athina, the trace will be visible in the Athina UI.