❊ Info
Note: this evaluator is very similar to Faithfulness but it returns a metric between 0 and 1.
How does it work?
- For every sentence in the
response, an LLM looks for evidence of that sentence in thecontext. - If it finds evidence, it gives that sentence a score of 1. If it doesn’t, it gives it a score of 0.
- The final score is the average of all the sentence scores.
Default Engine:
gpt-3.5-turbo
Required Args
context: The context that your response should be grounded toresponse: The LLM generated response
Groundedness: Number of sentences in the response that are grounded in the context divided by the total number of sentences in the response.- 0: None of the sentences in the response are grounded in the context
- 1: All of the sentences in the response are grounded in the context
Example
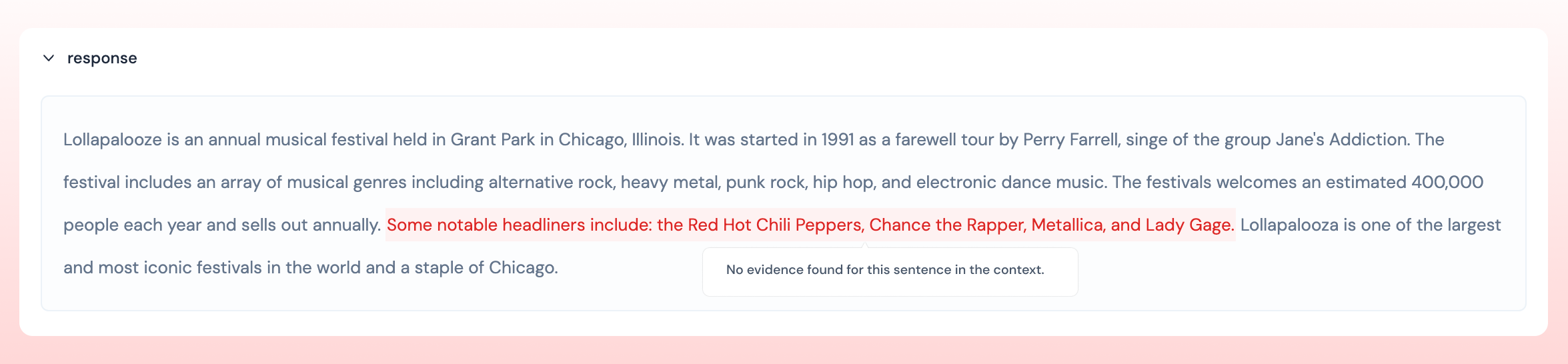
In Athina’s UI, sentences that are not grounded in the context are highlighted in red.
- Context: Y Combinator was founded in March 2005 by Paul Graham and Jessica Livingston as a way to fund startups in batches. YC invests $500,000 in 200 startups twice a year.
- Response: YC was founded by Paul Graham and Jessica Livingston. They invests $500k in 200 startups twice a year. In exchange, they take 7% equity.
▷ Run the eval on a dataset
- Load your data with the
Loader
- Run the evaluator on your dataset