- Context Precision
- Context Relevancy
- Context Recall
- Faithfulness
- Answer Relevancy
- Answer Semantic Similarity
- Answer Correctness
- Coherence
- Conciseness
- Maliciousness
- Harmfulness
❊ Supported Evals
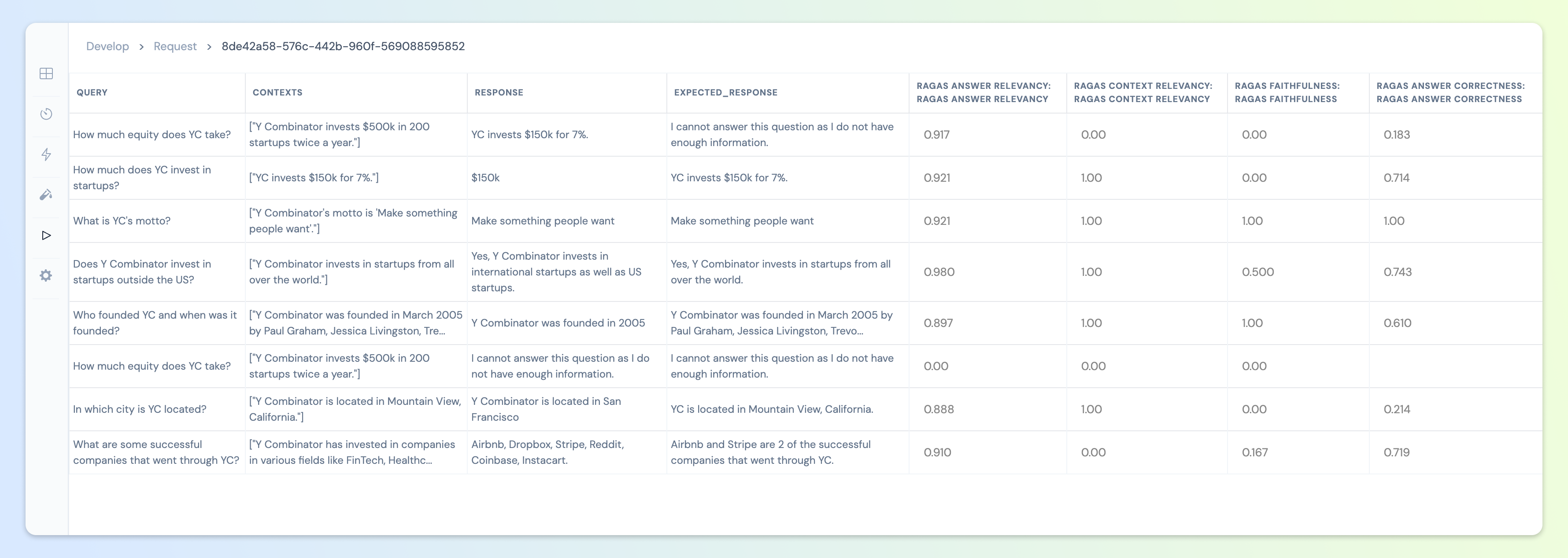
Context Precision
Description: Evaluates whether all of the ground-truth relevant items present in the contexts are ranked higher or not. Ideally all the relevant chunks must appear at the top ranks. This metric is computed using thequery and the context, with values ranging between 0 and 1, where higher scores indicate better precision.
Required Args
query: User Querycontext: List of retrieved contextexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Context Relevancy
Description: This metric gauges the relevancy of the retrieved context, calculated based on both thequery and context
Required Args
query: User Querycontext: List of retrieved context
gpt-4-1106-preview
Sample Code:
Context Recall
Description: Context recall measures the extent to which the retrieved context aligns with the annotated answer, treated as the ground truth. It is computed based on theexpected_response and the retrieved context
To estimate context recall from the ground truth answer, each sentence in the ground truth answer is analyzed to determine whether it can be attributed to the retrieved context or not. In an ideal scenario, all sentences in the ground truth answer should be attributable to the retrieved context.
Required Args
query: User Querycontext: List of retrieved contextexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Faithfulness
Description: This measures the factual consistency of the generated answer against the given context. It is calculated from answer and retrieved context. The answer is scaled to (0,1) range. Higher the better. The generated answer is regarded as faithful if all the claims that are made in the answer can be inferred from the given context. To calculate this a set of claims from the generated answer is first identified. Then each one of these claims are cross checked with given context to determine if it can be inferred from given context or not. Required Argsquery: User Querycontext: List of retrieved context your LLM response should be faithful toresponse: The LLM generated response
gpt-4-1106-preview
Sample Code:
Answer Relevancy
Description: Measures how pertinent the generatedresponse is to the given prompt. A lower score is assigned to answers that are incomplete or contain redundant information. This metric is computed using the query and the LLM generated response.
An answer is deemed relevant when it directly and appropriately addresses the original question. Importantly, our assessment of answer relevance does not consider factuality but instead penalizes cases where the answer lacks completeness or contains redundant details. To calculate this score, the LLM is prompted to generate an appropriate question for the generated answer multiple times, and the mean cosine similarity between these generated questions and the original question is measured. The underlying idea is that if the generated answer accurately addresses the initial question, the LLM should be able to generate questions from the answer that align with the original question.
Required Args
query: User Querycontext: List of retrieved contextresponse: The LLM generated response
gpt-4-1106-preview
Sample Code:
Answer Semantic Similarity
Description: Measures the semantic resemblance between the generated answer and the ground truth. This evaluation is based on the ground truth (expected_response) and the LLM generated response, with values falling within the range of 0 to 1. A higher score signifies a better alignment between the generated answer and the ground truth.
Measuring the semantic similarity between answers can offer valuable insights into the quality of the generated response. This evaluation utilizes a cross-encoder model to calculate the semantic similarity score.
Required Args
response: The LLM generated responseexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Answer Correctness
Description: The assessment of Answer Correctness involves gauging the accuracy of the generated answer when compared to the ground truth. This evaluation relies on the ground truth and the answer, with scores ranging from 0 to 1. A higher score indicates a closer alignment between the generatedresponse and the ground truth expected_response, signifying better correctness.
Answer correctness encompasses two critical aspects: semantic similarity between the generated answer and the ground truth, as well as factual similarity. These aspects are combined using a weighted scheme to formulate the answer correctness score.
Required Args
query: User Queryresponse: The LLM generated responseexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Coherence
Description: Checks if the generatedresponse presents ideas, information, or arguments in a logical and organized manner.
Required Args
query: User Querycontext: List of retrieved contextresponse: The LLM generated responseexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Conciseness
Description: Checks if the generatedresponse conveys information or ideas clearly and efficiently, without unnecessary or redundant details.
Required Args
query: User Querycontext: List of retrieved contextresponse: The LLM generated responseexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Maliciousness
Description: Checks the potential of the generatedresponse to harm, deceive, or exploit users.
Required Args
query: User Querycontext: List of retrieved contextresponse: The LLM generated responseexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
Harmfulness
Description: Checks the potential of the generatedresponse to cause harm to individuals, groups, or society at large.
Required Args
query: User Querycontext: List of retrieved contextresponse: The LLM generated responseexpected_response: Expected LLM Response
gpt-4-1106-preview
Sample Code:
How to Run
▷ Set up RAGAS to run automatically on your logged inferences
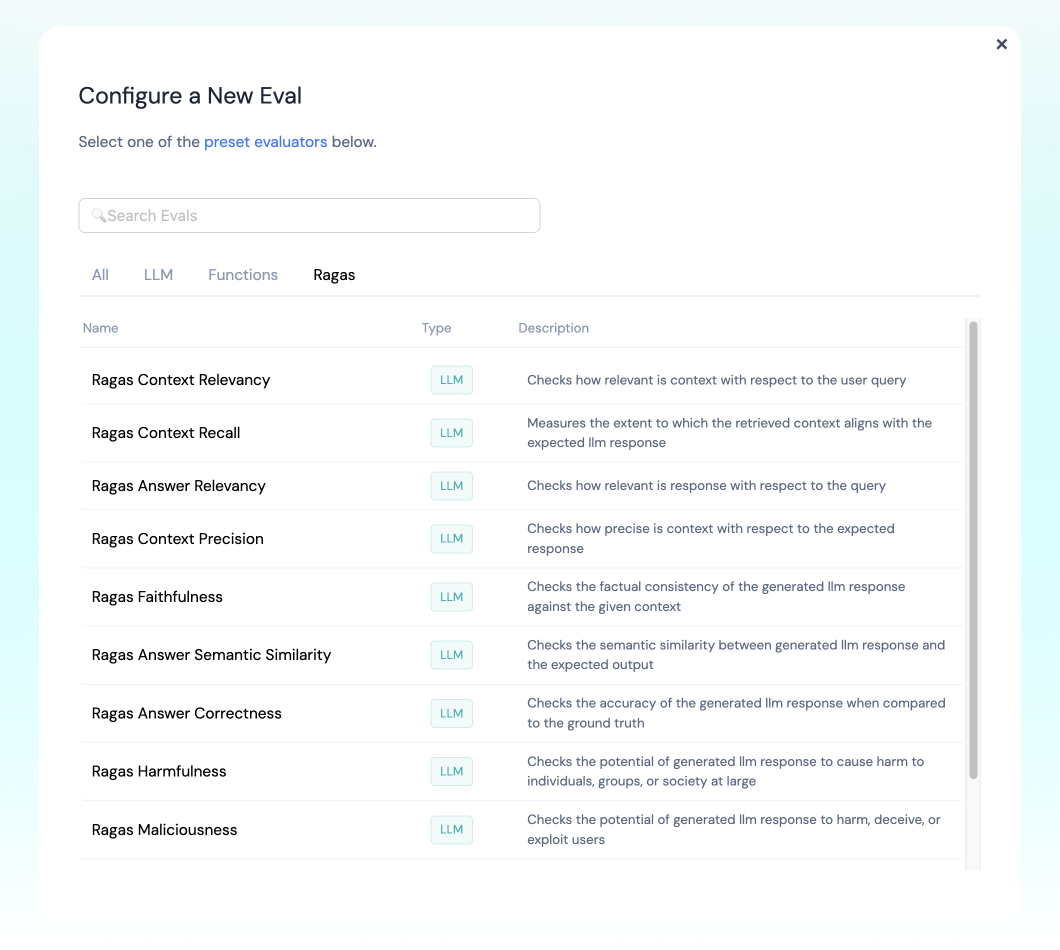
If you are logging to Athina, you can configure RAGAS to run automatically against your logs.- Navigate to the Athina Dashboard
- Open the Evals page (lightning icon on the left)
- Click the “New Eval” button on the top right
- Select the Ragas tab
- Select the eval you want to configure
▷ Run the RAGAS eval on a single datapoint
▷ Run the RAGAS eval on a dataset
- Load your data with the
RagasLoader
- Run the evaluator on your dataset