Why use Athina for Fine-Tuning Data Preparation?
In Athina, data preparation is easy with Dynamic Columns, allowing users to clean, transform, and format datasets without complex coding. You can detect errors, duplicates, and inconsistencies in datasets and even create custom evaluations to ensure data quality before fine-tuning. This results in optimized, high-quality data for better fine-tuning outcomes. Now, let’s go through the step-by-step process of preparing data for fine-tuning.Implementation
We are fine-tuning the TinyLlama (1.1B parameters) model with a 2048-token context window (Sequence Length), so the total token length for each sample must be ≤ 2048.
Step 1: Checking Sequence Length
1
To check the token length for both questions and answers, we will create a tokenizer flow as shown below: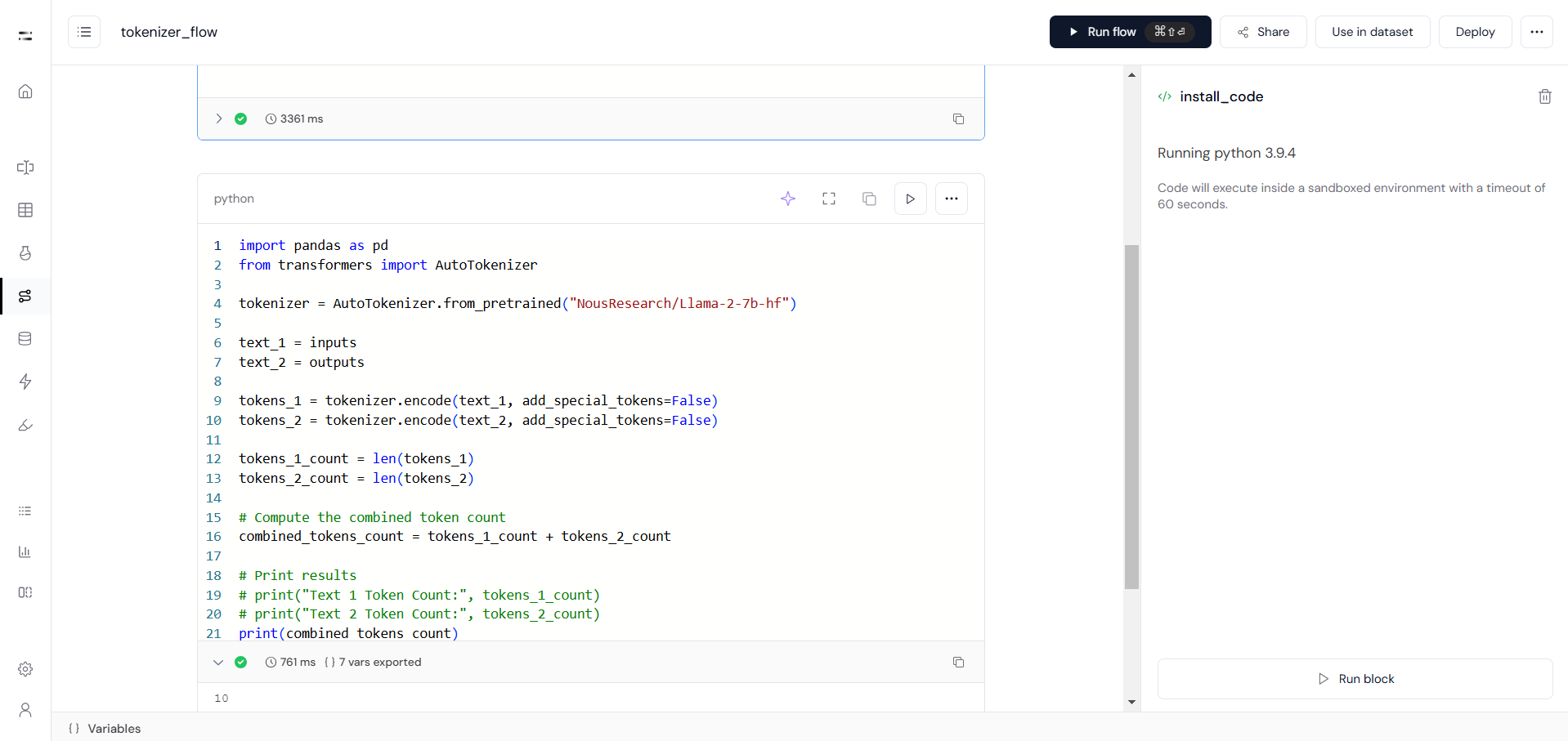
2
Next, click on “Use in Dataset” to add this flow to the fine-tuning dataset.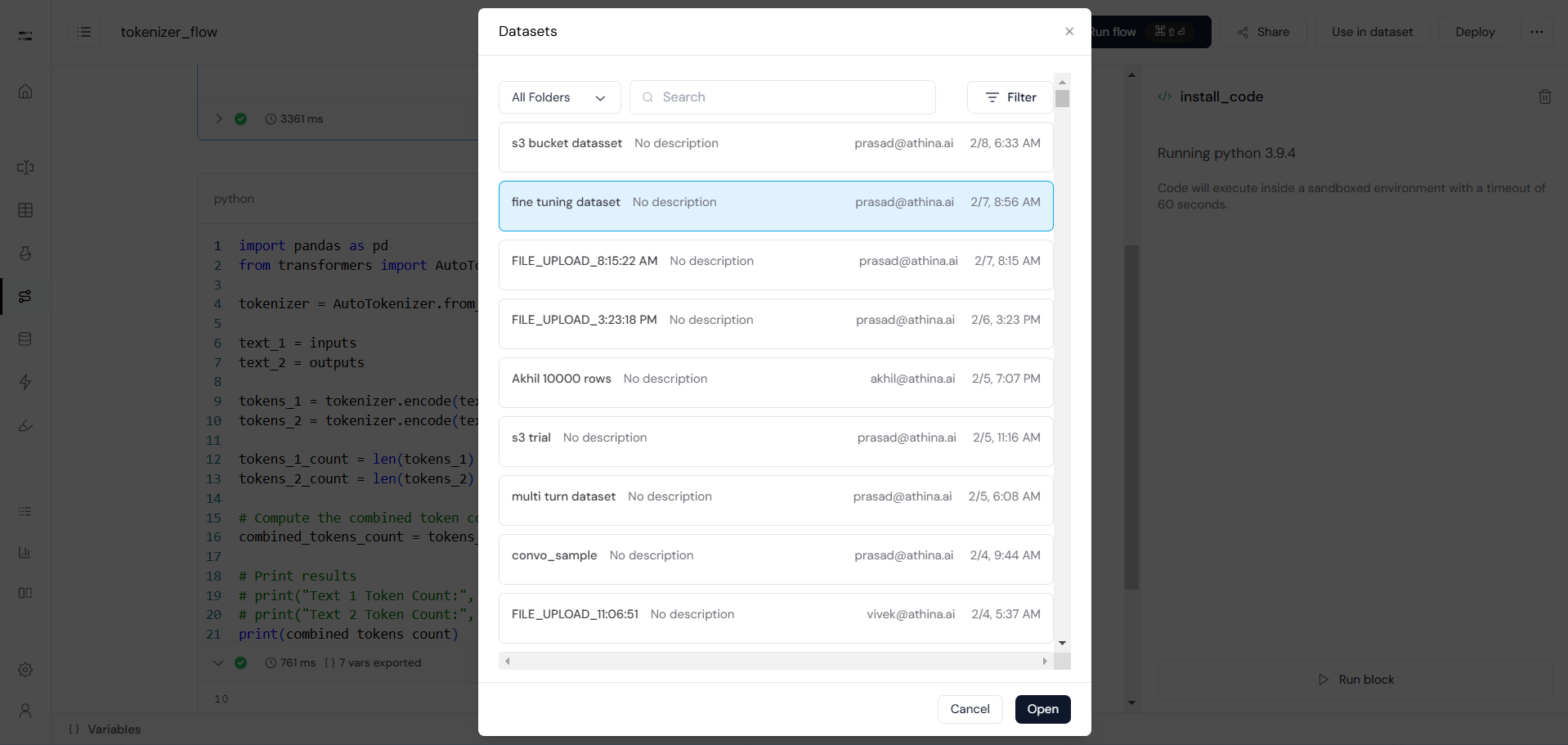
3
You will then be redirected to your dataset. Here, select Configure Inputs and choose the second code block as the output. This will appear in the dataset column, as shown below: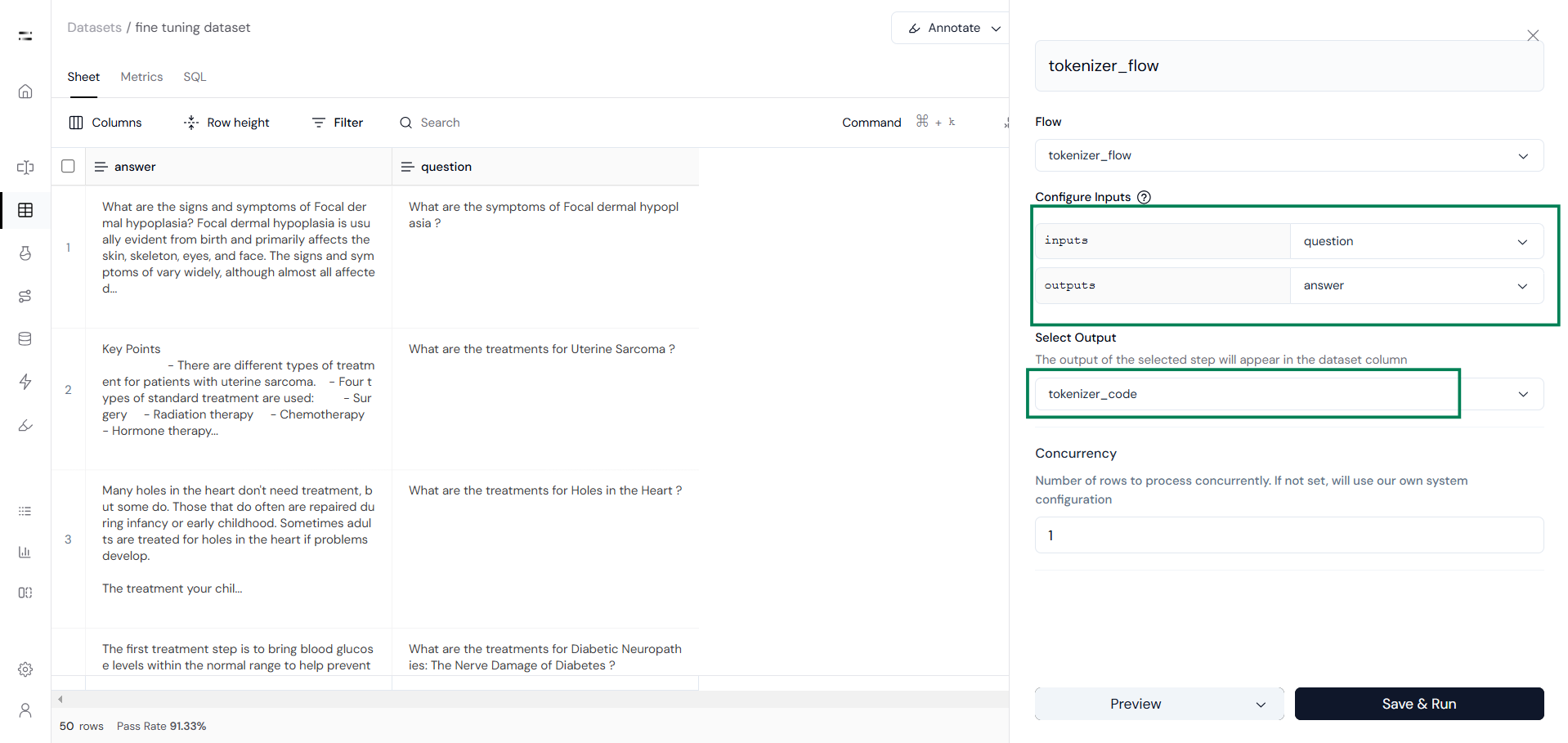
4
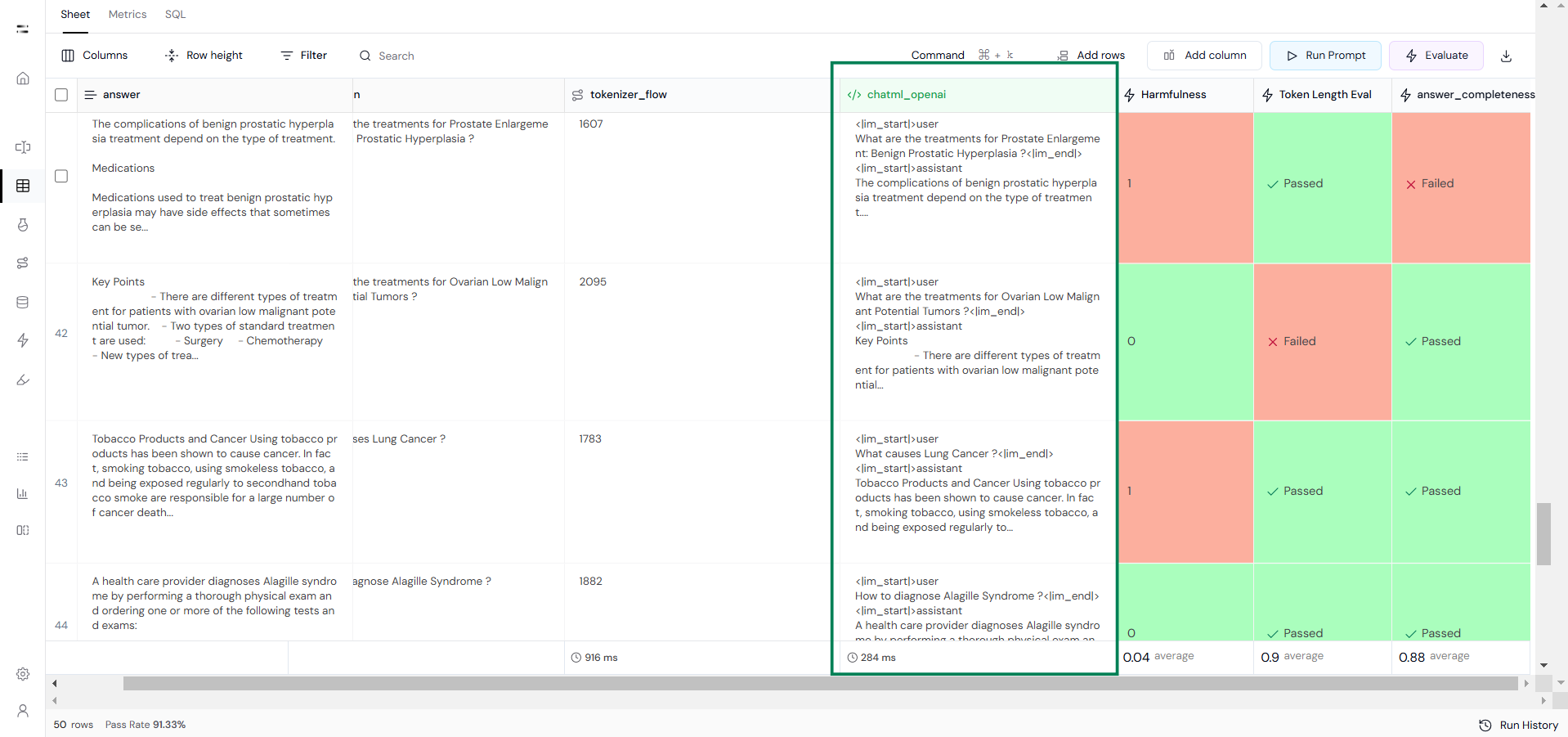
After this, create a custom evaluation to check whether the response exceeds the 2048-token context window.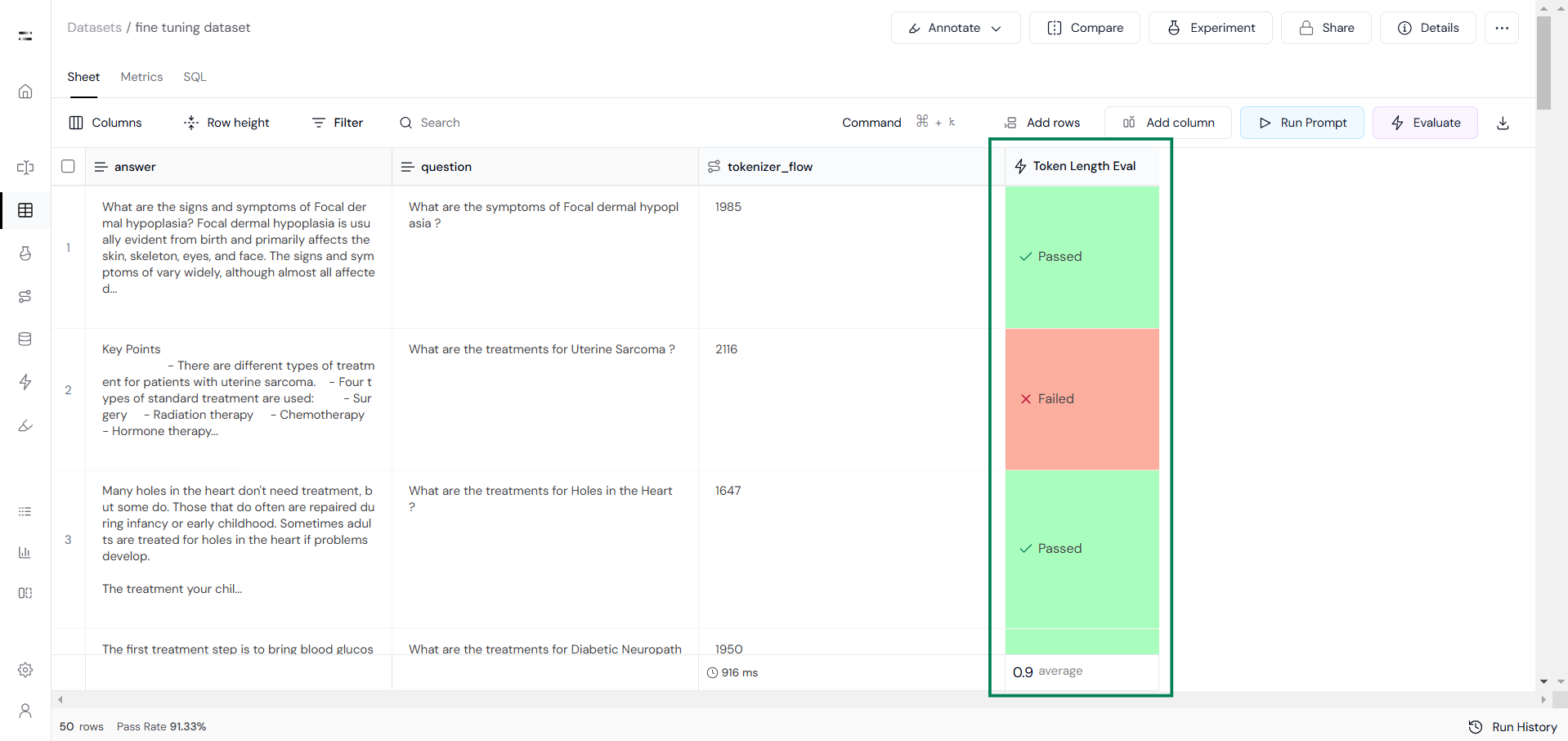
Step 2: Quality Checking
1
Ensure data quality using evaluation metrics such as: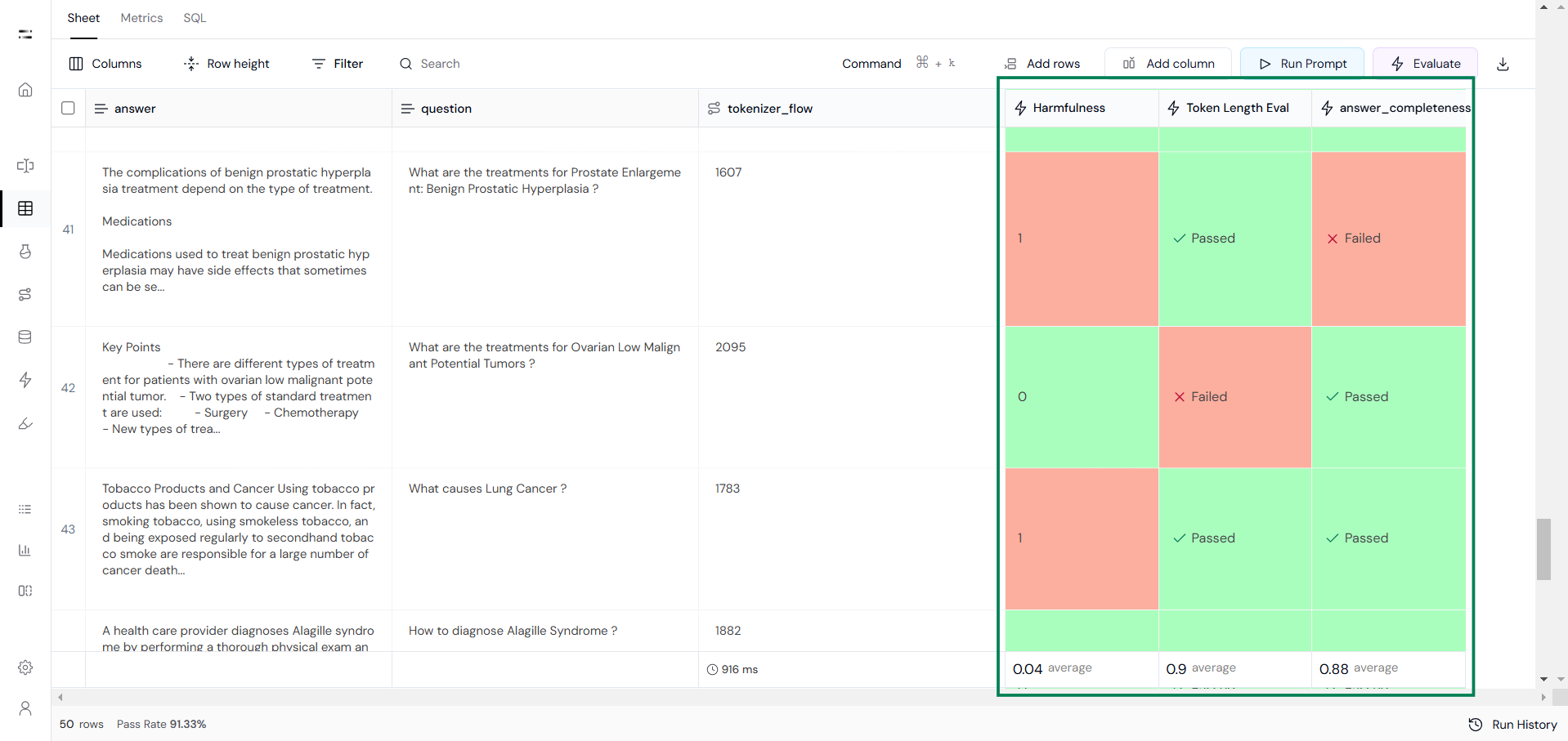
- Answer completeness
- Grammar accuracy
- Safety checks (e.g., harmfulness or maliciousness)
You can also create custom evaluations (as per your use case) to check the quality of the dataset.
Step 3: Applying the Chat Template
1
Once high-quality data has been selected, apply the Chat Template using Execute Custom Code. Here, we use the ChatML template from OpenAI.