Introduction
A common key challenge in developing or improving prompts and models is determining whether a new configuration performs better than an existing one. Pairwise evaluation addresses this by comparing two responses side by side based on specific criteria such as relevance, accuracy, or fluency. Traditionally conducted by human reviewers, this process can be time-consuming, costly, and subjective. Tools like Athina AI automate pairwise evaluation using LLMs, making it faster, scalable, and more efficient. This guide explains what pairwise evaluation is, where it can be used, and how to perform it using Athina AI.
Let’s start by understanding what pairwise evaluation is.
What is Pairwise Evaluation?
Pairwise evaluation is a method for comparing two outputs from different prompts or models to determine which performs better. This comparison is based on criteria such as relevance, accuracy, or fluency. For example, you can compare responses from an old and a new model to identify improvements. This method is widely used by AI teams as part of their evaluation processes. While traditionally conducted by human reviewers, pairwise evaluation can also be automated using LLMs, provided the grading criteria are well-defined. Using automated tools like Athina, you can evaluate more efficiently and at a larger scale, with less subjectivity.Where to Use Pairwise Evaluation?
Pairwise evaluation is highly versatile and can be applied in various scenarios, including:- Comparing Models: Compare outputs before and after fine-tuning to determine if the updates improved performance.
- Prompt Optimization: Test different prompt configurations to identify the one that delivers the best results.
- Application Development: Evaluate model outputs for use cases like chatbots, virtual assistants, and customer service systems to ensure they meet quality standards.
- Feature Testing: Assess the impact of new features or model versions by directly comparing them to previous versions.
- Quality Assurance: Identify and address potential issues like relevance gaps, factual inaccuracies, or unclear responses in generated outputs.
Dataset
In this guide, we will perform a pairwise evaluation on the Ragas WikiQA dataset, which contains questions, context, and ground truth answers. This dataset is generated using information from Wikipedia pages.Pairwise Evaluation in Athina AI
Now let’s see the step-by-step process of creating pairwise evaluation in Athina AI:Step 1: Generate Response Sets
1
Start by creating two sets of responses using two different models as you can see in the following images.Run Prompt to generate responses: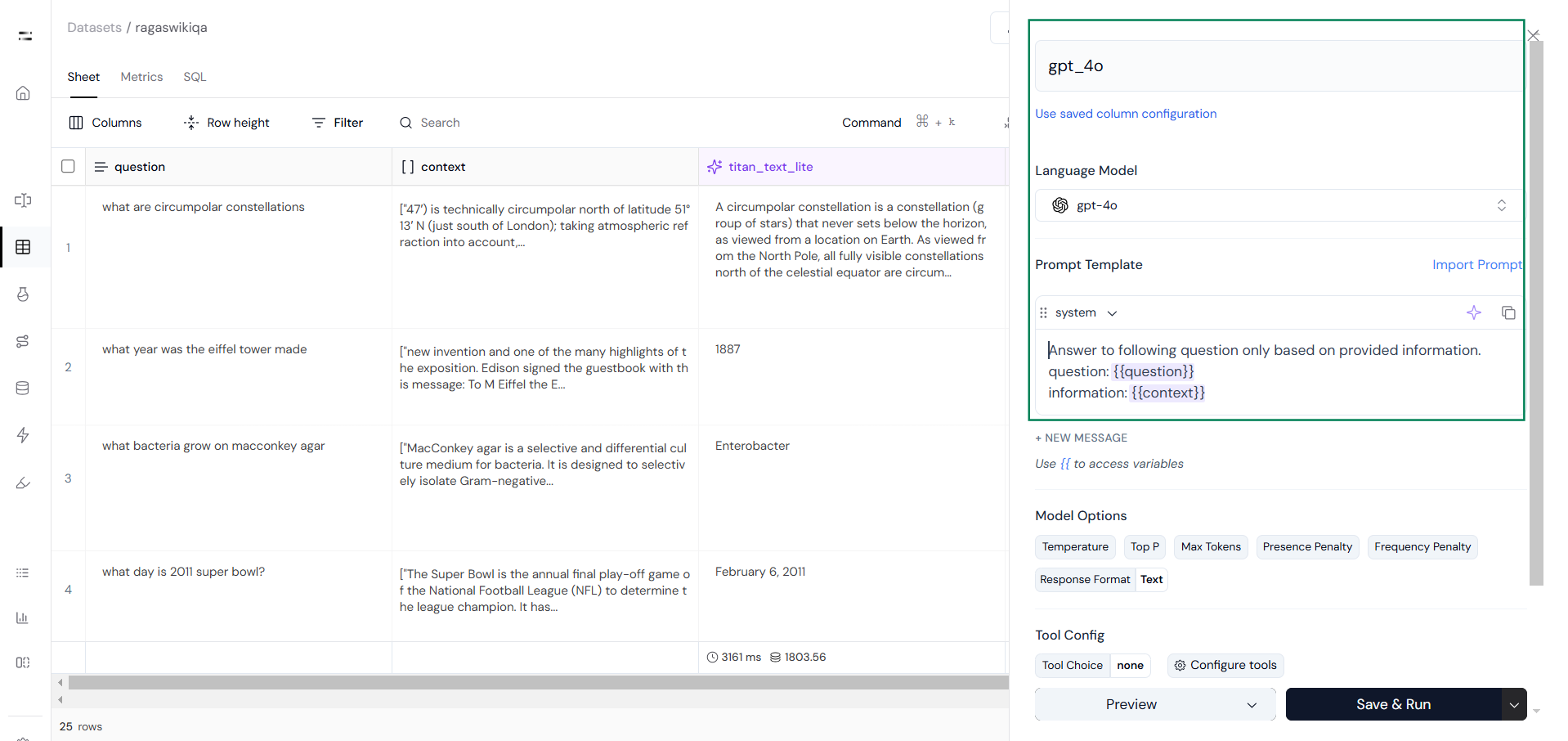
2
Output from both models will look something like this: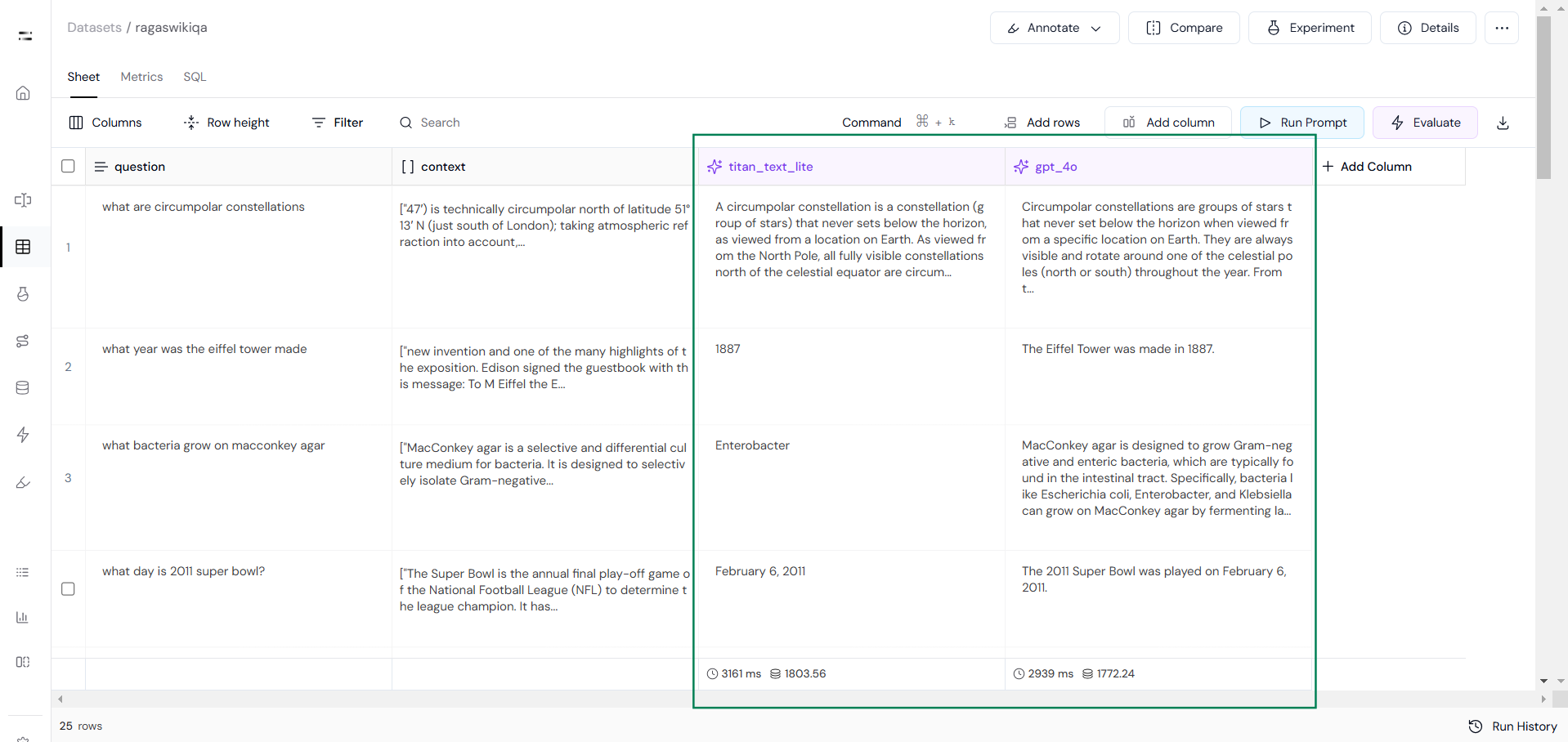
Step 2: Define Evaluation Criteria
1
Next, click on the Evaluate feature, then select Create New Evaluation and choose the Custom Eval option.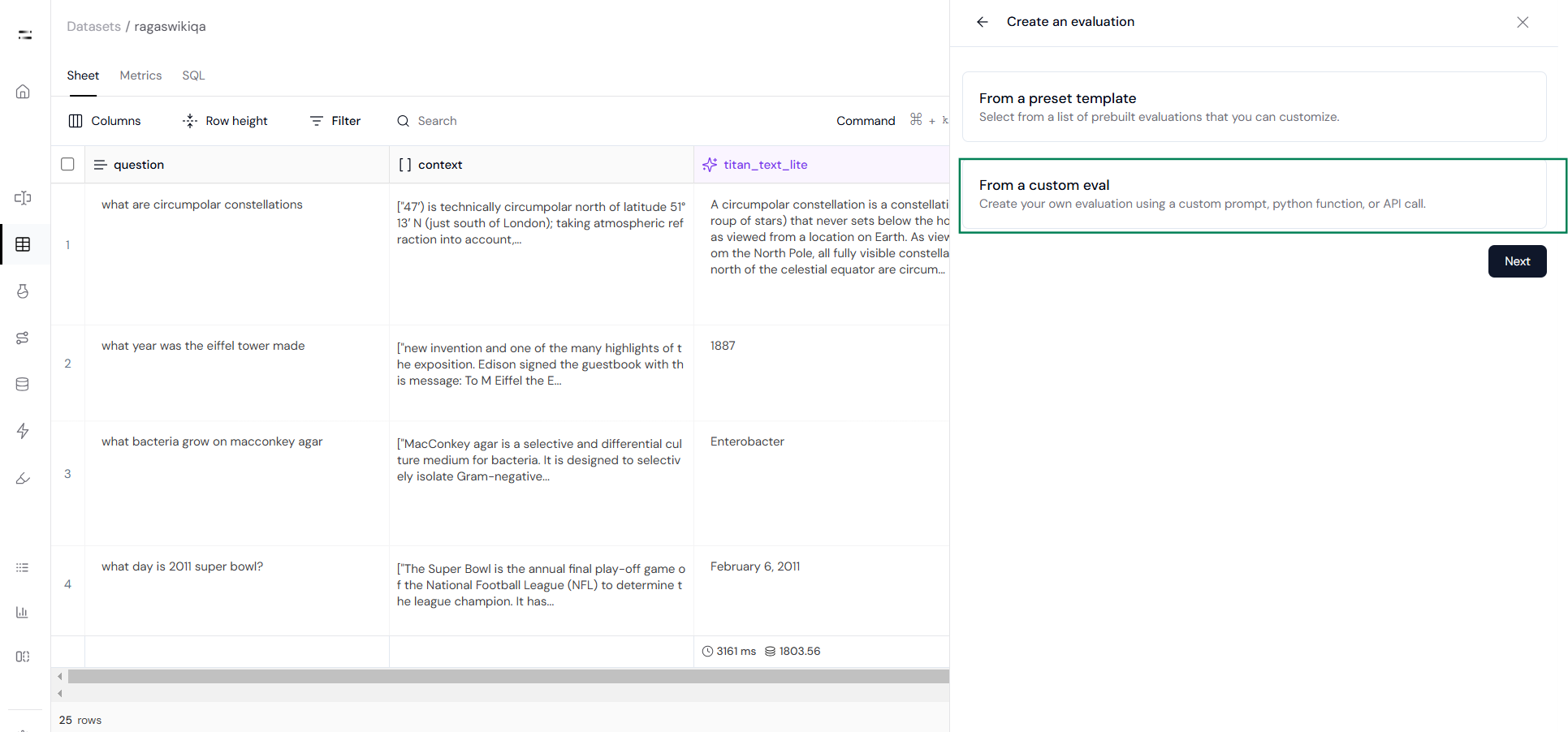
2
Then click on the custom prompt option as you can see below: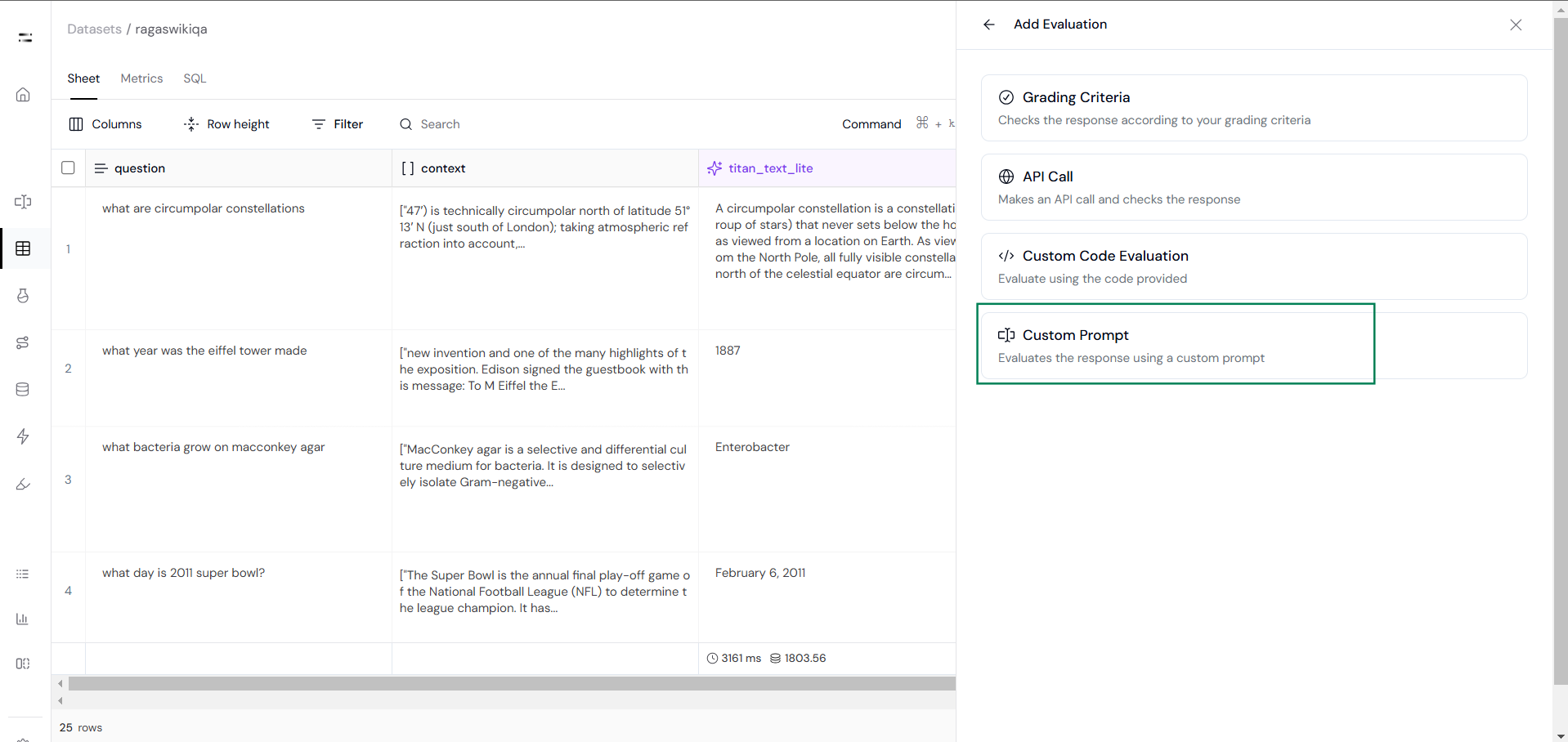
3
Now define your pairwise evaluation prompt. For example, if the model 1 response is better, then return 1, and if the model 2 response is better, then return 2.
Here is a sample pairwise evaluation prompt: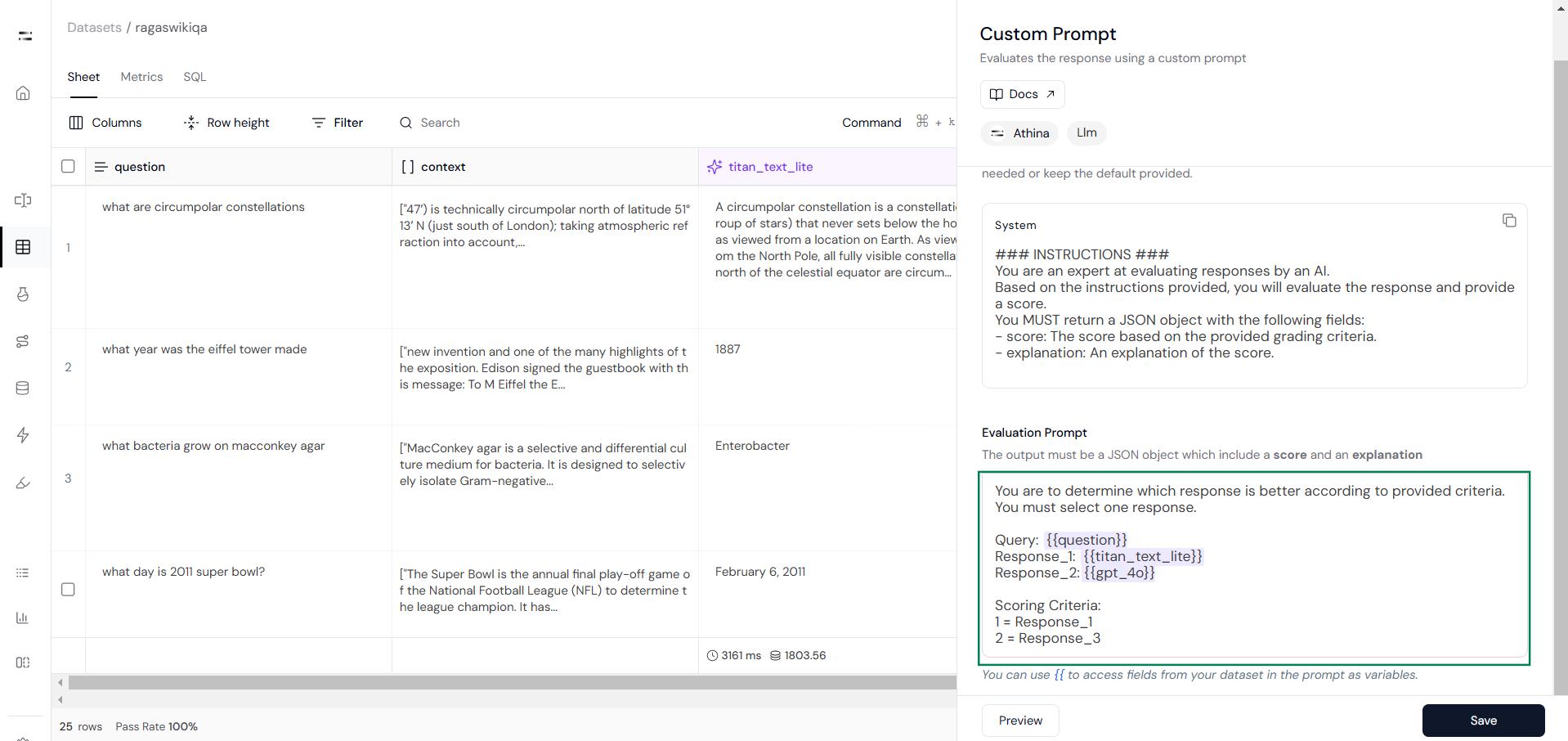
Step 3: Run the Evaluation
1
Then, run the evaluation to compare each pair of responses based on the defined criteria.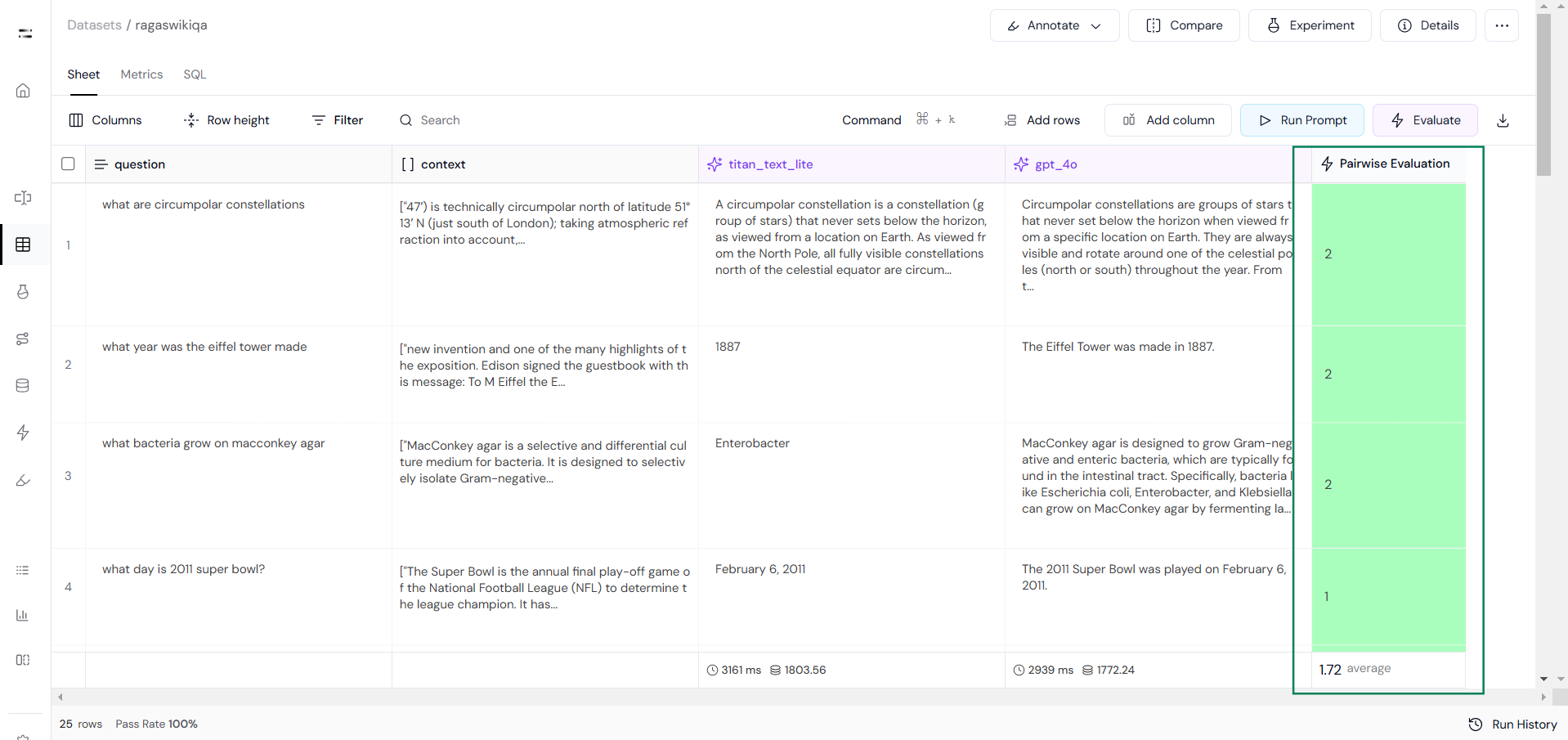
Step 4: Compare Results
1
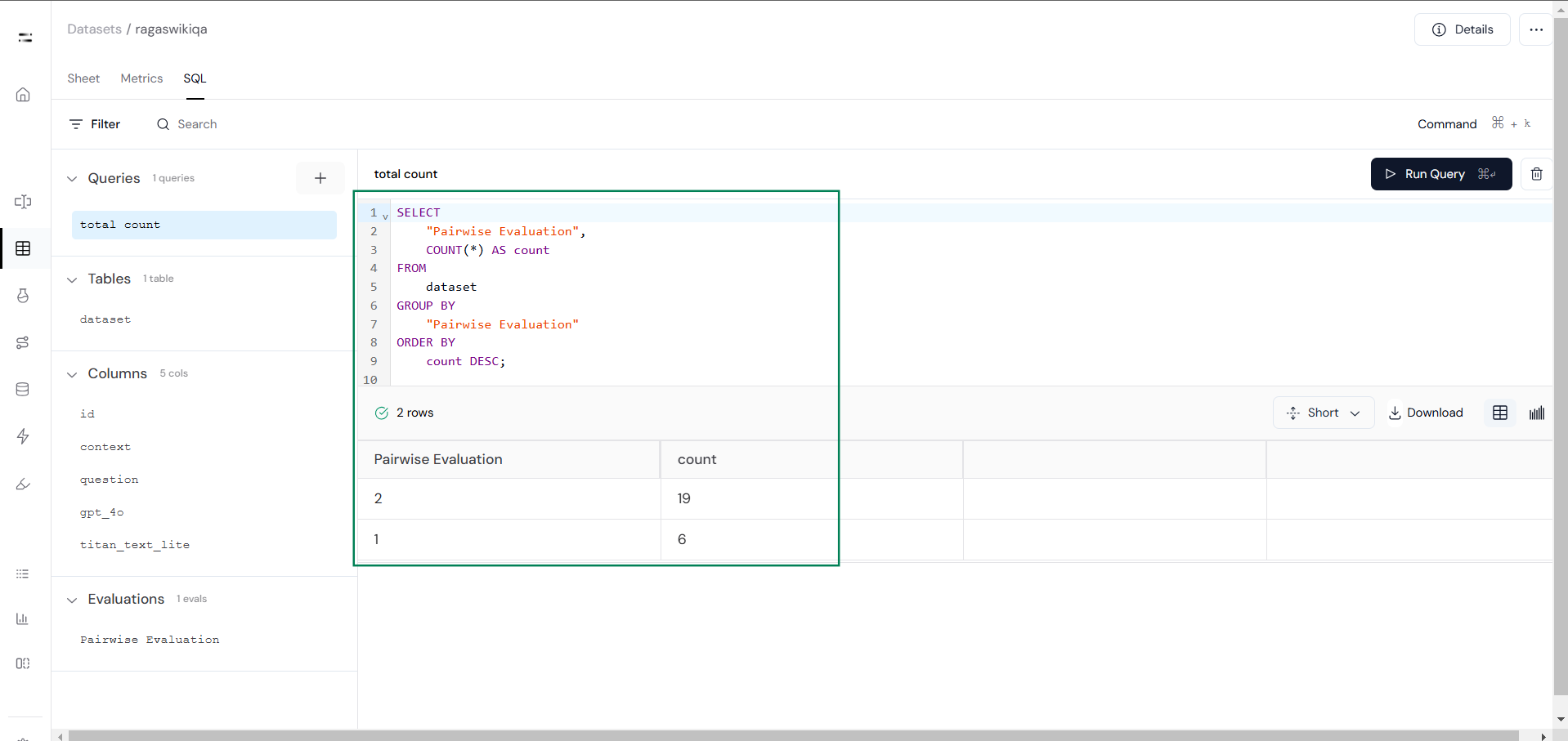
Once the evaluation is complete, go to the SQL Section to view and compare the scores. This analysis will help you determine which model performed better across the dataset.