Common Failures in RAG-based LLM apps
RAG-based LLM apps are great, but there are always a lot of kinks and imperfections to iron out. Here are some common ones: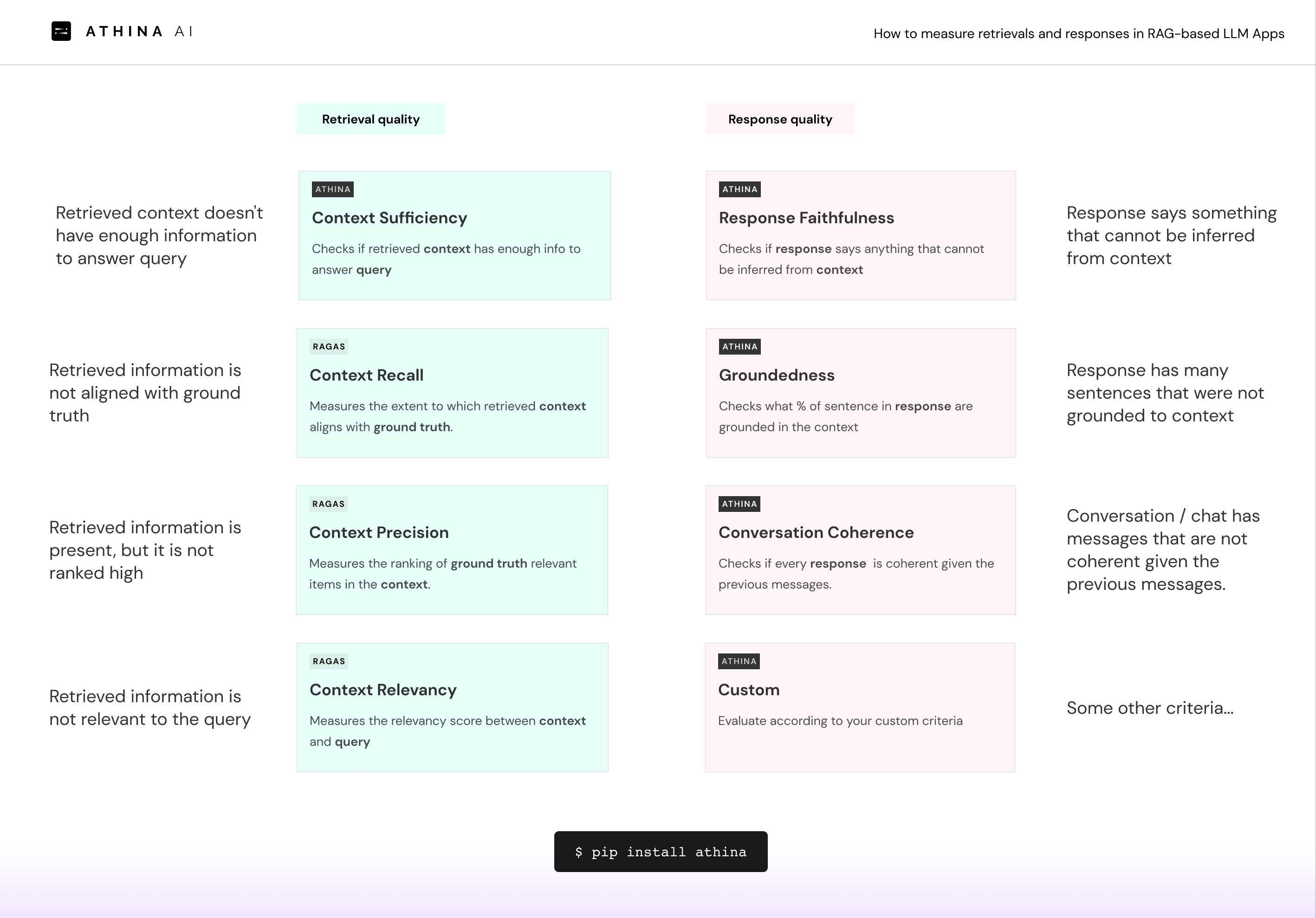
Bad retrieval
- Retrieved information is not aligned with ground truth (Context Recall)
- Retrievals are present but they are not ranked high (Context Precision)
- Retrieved information doesn’t have enough information to answer query (Context Sufficiency)
- Retrieved information is not relevant to the query (Context Relevancy)
Bad outputs
- Response says something that cannot be inferred from context (Faithfulness)
- Response has many sentences that were not grounded to context. (Groundedness)
- Conversation / chat has messages that are not coherent given the previous messages. (Conversation Coherence))
- Some other criteria… (Custom Evaluation)