Evaluating logs in production is the only way to know if your LLM application
is working correctly in the real world.
Why use Athina for Online Evals?
- 50+ preset evals
- Support for custom evals
- Support for popular eval libraries like Ragas, Guardrails, etc
- Sampling: sample a subset of logs
- Filtering: only run on logs WHERE X is true
- Rate limiting: intelligent throttling to avoid rate limiting issues with your LLM provider
- Use any model provider for LLM evals
- View aggregate analytics
- View traces with eval results
- Track eval results over time
How does it work?
This is a simplified view of the architecture used to run evals on logged inferences in production at scale.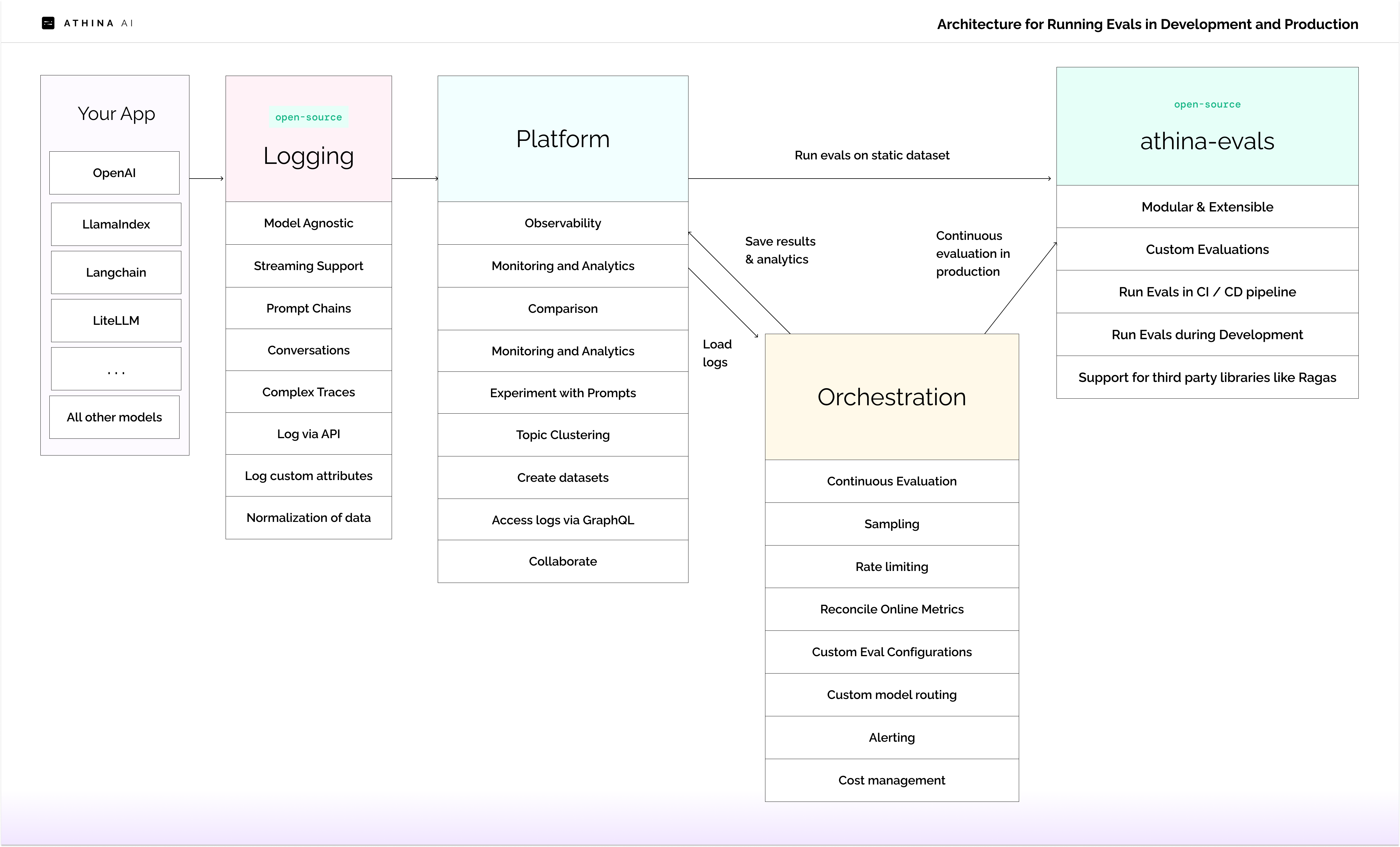
Key Features
Run the same evaluations in dev, CI / CD, and prod
Run the same evaluations in dev, CI / CD, and prod
Athina’s core evaluation framework is open source and can be used to run the same evaluations in development, CI / CD, and production.See it on Github: athina-evals
Observability
Observability
Athina provides a complete observability platform for your LLM application:
- Detailed trace inspection
- Manual annotation capabilities
- Unified online/offline metrics
- PagerDuty and Slack integrations
- Data export functionality
- API/GraphQL access
Production-Grade Evaluation Without Ground Truth
Production-Grade Evaluation Without Ground Truth
Evaluate your LLM applications in production with confidence: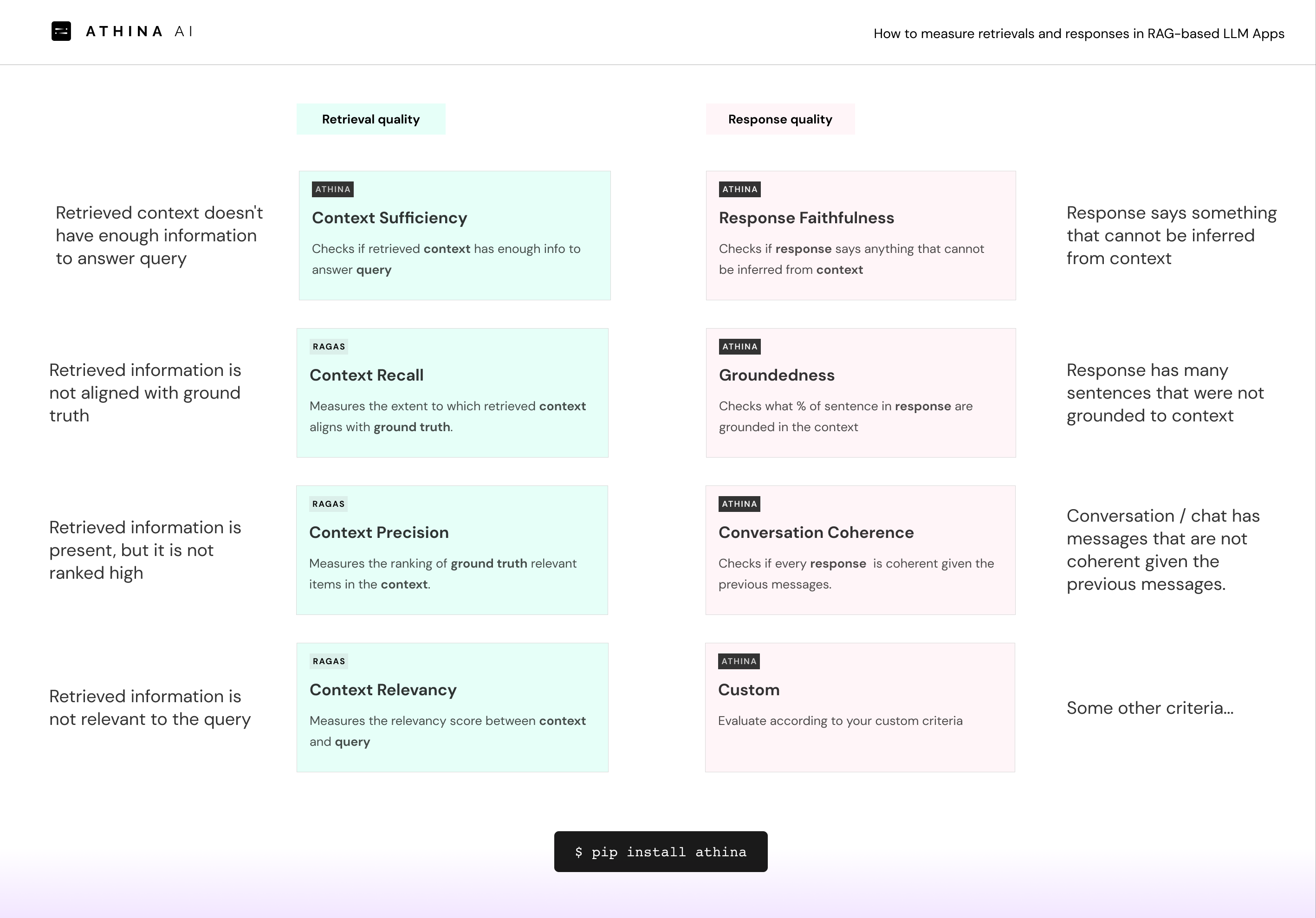
- Advanced LLM-based evaluation techniques for measuring retrieval and response quality
- State-of-the-art research-backed evaluation metrics
- Continuous improvement of evaluation methodologies
Cost Management
Cost Management
Maximize evaluation coverage while minimizing costs:
- Smart sampling strategies
- Configure evals to run on only a subset of logs based on filters
- Comprehensive cost tracking and optimization
- Configurable evaluation frequency
Flexible Evaluation Framework (Open Source)
Flexible Evaluation Framework (Open Source)
Comprehensive evaluation capabilities:
- Rich library of 50+ preset evals
- Customizable evaluation configurations
- Build and deploy custom evals
- Multiple model provider support
- Seamless integration with popular eval libraries (Ragas, Guardrails, etc)
Enterprise-Scale Automation
Enterprise-Scale Automation
Fully automated evaluation pipeline:
- Scalable evaluation infrastructure
- Centralized eval configuration management
- Smart eval-to-prompt matching
- Intelligent rate limiting
- Multi-provider model support
- Historical log evaluation capabilities
Universal Architecture Support
Universal Architecture Support
Seamlessly adapt to any LLM stack:
- Multi-provider support (OpenAI, Gemini, etc)
- Framework-agnostic (Langchain, Llama Index, custom)
- Complex trace and agent support
- Flexible architecture adaptation
- Standardized evaluation layer
View Traces with Eval Results
View Traces with Eval Results
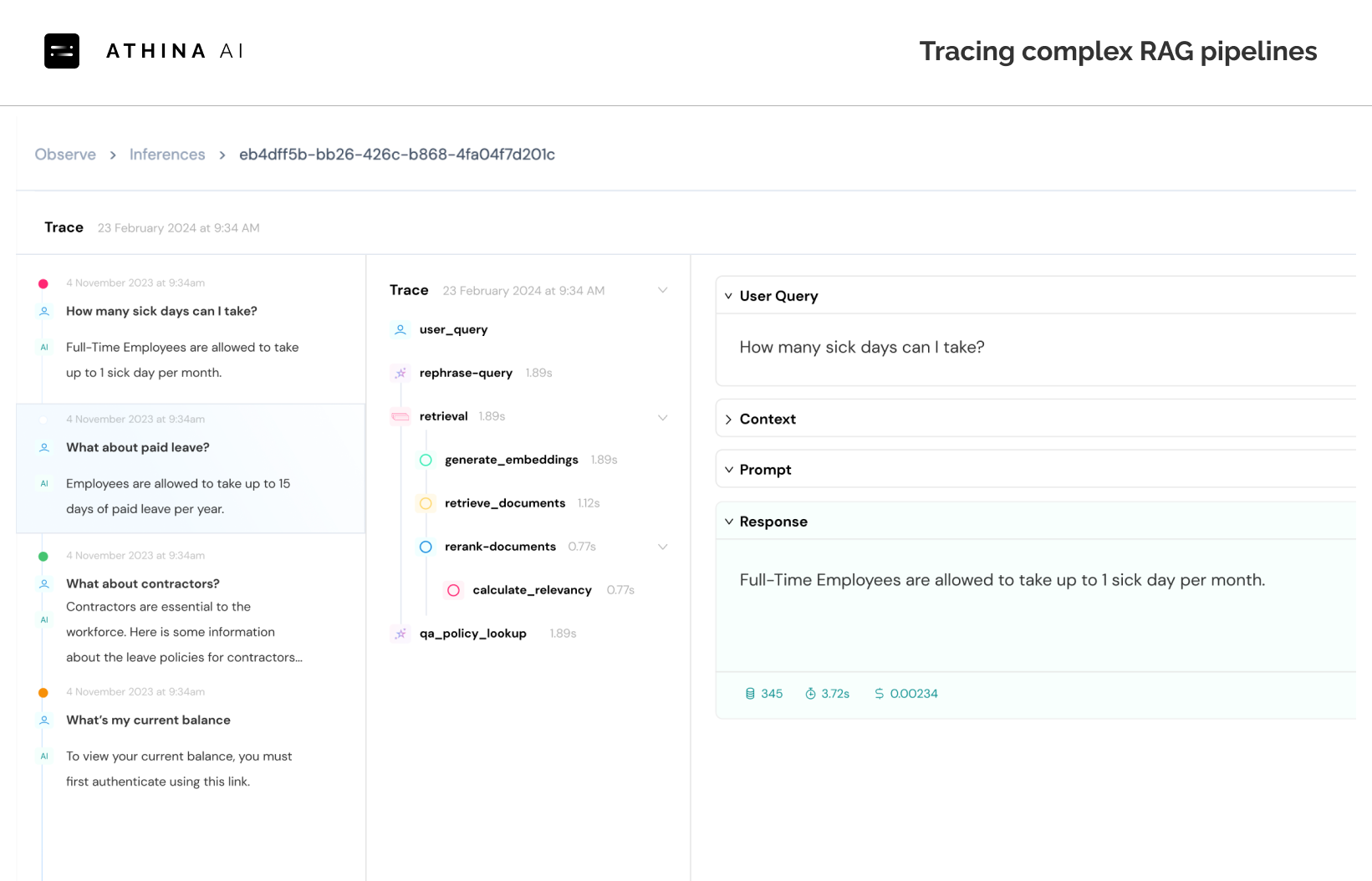
Comprehensive Analytics Suite
Comprehensive Analytics Suite
Deep insights into your LLM application: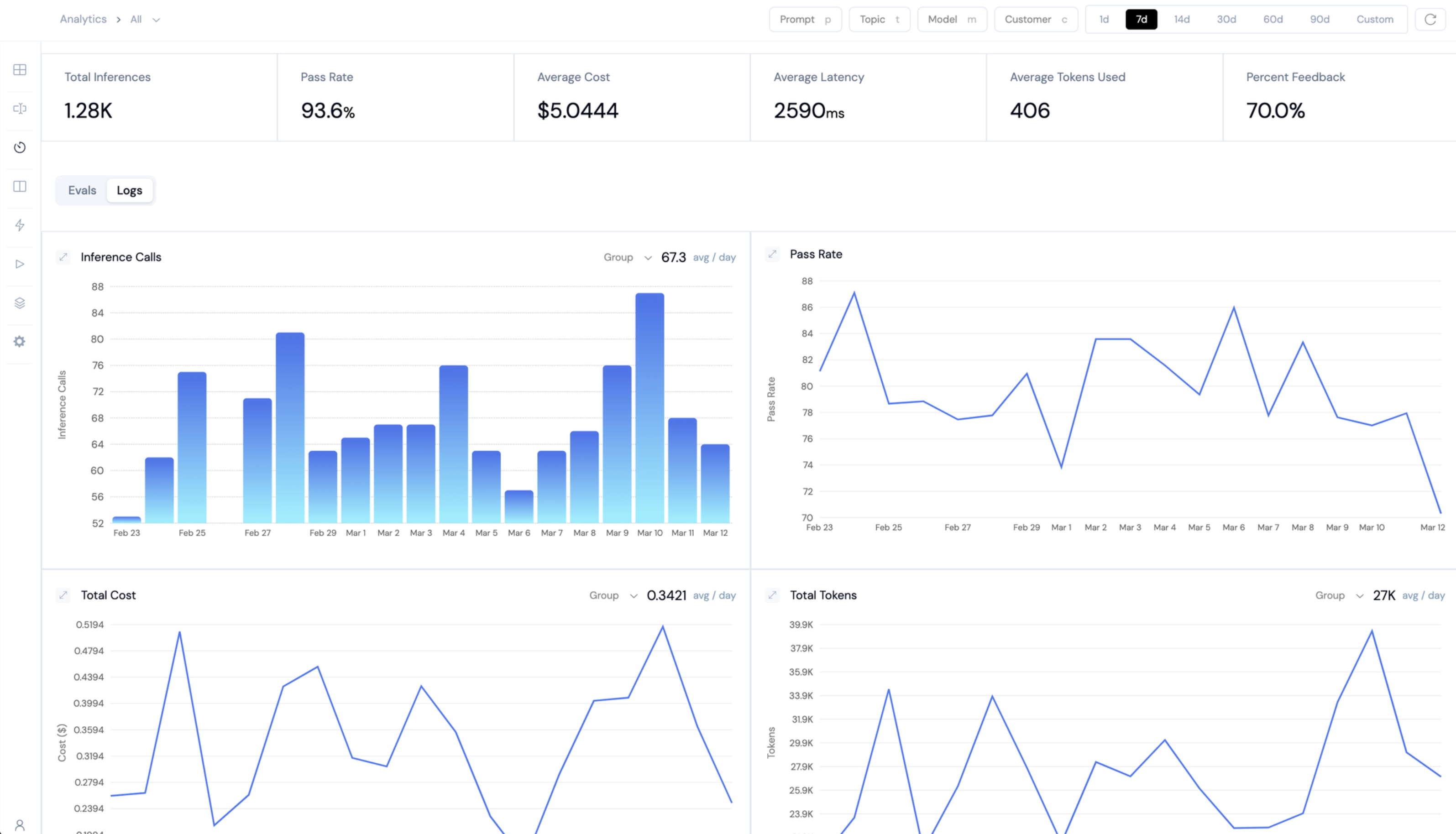
- Application performance metrics
- Retrieval quality analytics
- Resource utilization tracking
- Safety and security monitoring
- Temporal analysis
- Statistical distribution insights
- Multi-dimensional segmentation
Team Collaboration
Team Collaboration
Enterprise-ready collaboration features:
- Team workspaces
- Role-based access control
- Workspace isolation
- Shared evaluation insights