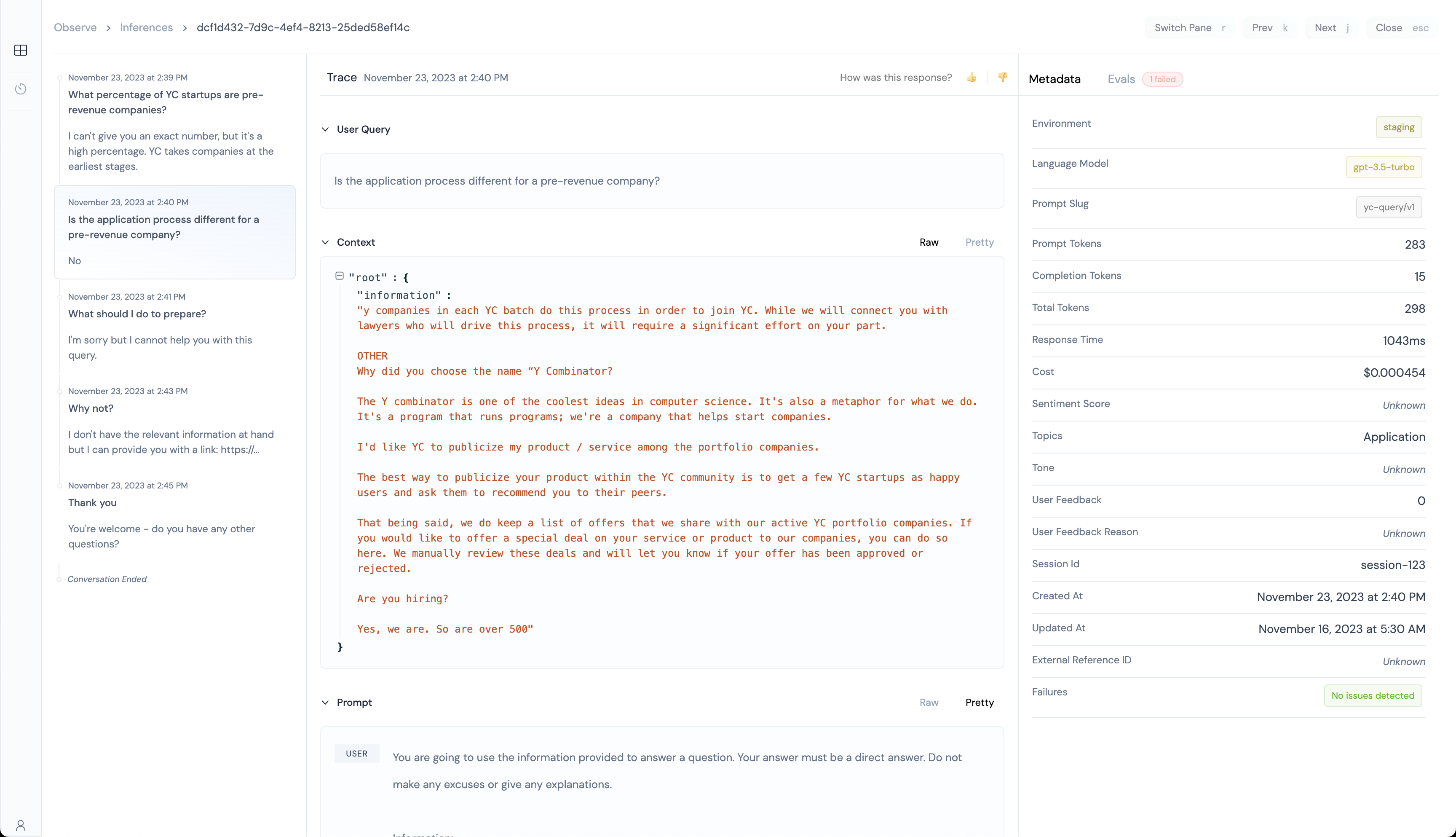
In addition, you can also see the following information:
- What was the sentiment score of the user query?
- What was the tone of the user query?
- What topic was the user query about?
- What was the token usage, cost, and response time of the inference?
- Did someone from your team grade this inference with a 👍 or 👎?
- What language model, and prompt version was used for this inference?
- Which user was this inference for?